
왜 데이터 전처리인가?
실제 데이터베이스에서 데이터 추출 정확한 데이터 없음머신 러닝이나 딥 러닝은 데이터가 양호해야 작동한다는 것을 알게 될 것입니다. 데이터가 좋지 않으면 최신 SOTA나 최고급 모델도 소용이 없다. (GIGO, 쓰레기 투입, 쓰레기 배출)
확실하지 않은 경우 Kaggle 또는 Dacon에 게시된 데이터를 다운로드하여 검토하십시오. 기본 타이타닉 데이터에서 현재 Age와 Cabin은 빈 데이터가 많습니다.
대회에 업로드된 데이터가 고도로 정제된 데이터라도 제공된 데이터를 그대로 사용하는 것은 불가능합니다.
여전히 확실하지 않은 경우 GPS를 사용하여 방향을 찾는 경험을 고려하십시오. 내 위치는 항상 옳았습니까? 별로.
인적 오류 또는 컴퓨터 오류가 있을 수 있습니다.
데이터 품질만 있으면 됩니다!
데이터 품질 측정
- 정확도: 데이터 값이 정확합니까?
- 인간 또는 컴퓨터 오류로 인한 부정확한 데이터 저장
- 사용자가 잘못 입력하여(예: 생일은 1월 1일, 알라바마에 거주) 시스템의 초기 값이 저장되어 있는 경우 이를 난독화된 누락 데이터라고 합니다.
- 버퍼 오버플로로 인한 데이터 전송 오류 또는 기술적 한계로 인한 동기화 오류
- 완전성: 데이터가 완전합니까?
- 누락된 값에는 몇 가지 이유가 있을 수 있습니다. (장비 고장으로 인해 기록되지 않음)
- 일관성: 데이터가 여러 속성에서 일관성이 있습니까?
- 상충되는 데이터가 있을 수 있습니다. (생일이 2010년 3월 7일이고 현재 만 40세인 경우)
- 데이터 기록 또는 변경 사항이 있을 수 있습니다. (과거에는 1, 2, 3점으로 저장되었으나 지금은 A, B, C로 저장됩니다.)
- 적시성: 데이터가 적시에(신속하게) 업데이트됩니까?
- 신뢰성: 데이터를 신뢰할 수 있음(최근에 오류를 수정했지만 과거에 이미 기록된 데이터는 아님)
- 해석 가능성: 데이터가 이해하기 쉬운가?
데이터 전처리의 주요 작업
1. 데이터 정리
- 누락된 값의 강화
- 소음 청소
- 이상값 감지/제거
- 모순을 해결하다
2. 데이터 통합
- 엔티티 식별 문제
- 중복성 및 상관관계 분석
- 튜플 복제
- 데이터 값 충돌 감지 및 해결
3. 데이터 축소
- 데이터 축소 전략 개요
- 웨이블릿 변환
- 주성분 분석, PCA
- 속성 하위 집합 선택
- 회귀 및 로그 선형 모델: 파라메트릭 데이터 감소
- 히스토그램
- 클러스터링
- 견본 추출
- 데이터 큐브 집계
4. 데이터 변환
- 데이터 변환 전략 개요
- 정규화를 통한 데이터 변환
- 비닝에 의한 이산화
- 히스토그램 분석에 의한 이산화
- 클러스터별 이산화, 의사 결정 트리 및 상관관계 분석
- 명목 데이터에 대한 개념 계층 생성
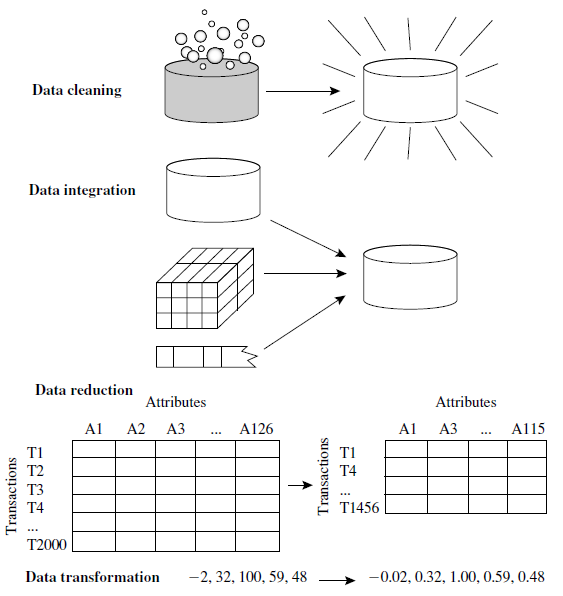
각 단계에 대해 자세히 설명하고 게시하겠습니다.
